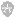IDC内网异常排障小技巧
2013-04-24 19:24:44 来源: 评论:0 点击:

注意:本文主要偏重内网故障排查.
当我们通过monitor发现业务异常或者故障时,检查后排除本身问题以及和相关业务系统无关后,大家这时候肯定会想到是网络或者基础架构问题,但是当我们简单地提供业务数据给到NOC时,NOC 90%情况下会回复:我们这边监控正常。这里不是说NOC或者公司的网管系统不给力,而是他们监控布点相比我们业务监控来说比较分散,不像我们业务之间通信这么敏感,很难对所有内部网络做全面监控,所以这里对我们提出了更高的要求-----具备把业务异常转化为发现基础架构尤其是网络异常的能力,这样才能更快解决问题。
我们向NOC报障时,NOC会要求提供以下数据:
1. 发生异常的地点-----IDC甚至楼层
2. 异常现象,比如丢包,时延变大,异地传输失败,超时等
3. 端到端的ping和traceroute数据
那么如何获得将业务异常转化为基础架构的异常呢,以下我们就来分享几个小技巧
技巧一:尽可能提供最准确和全面的数据
1. 确认准确的端到端IDC和IP
想要获得快速的解决,提供准确的信息非常重要,回答以下问题
a 源和目的IP在异地,同城,同idc,同一个楼层甚至同一个交换机下面?
b 是否有跨异地专线或者同城专线?
c 源IP和目的IP有无聚集性?是1—>n ,nà1还是nàn?
2. 准确完整的现象描述
例如:深圳到天津走pos专线的数据同步失败;
沙河内网两个两批ip之间通信超时
同一个交换机下面某个ip到其它ip 之间ping时延变长,而且是双向
3. 提供IP列表(如果有)
技巧二:具备简单的故障判断能力
我们自己如果能具备简单的故障判断能力,大多数情况下会减少故障时间,快速恢复服务
下面我们就常见的故障为例分析
1. 上联交换机带宽跑满
现象:某个接入交换机下面的机器聚集性ping丢包,或者业务大量超时
原因:交换机下面的某个或多个机器流量突增,把交换机上联带宽跑满了,2.0版本架构的网络比较多见,3.0以上的网络比较少了
查找方法:在网管系统(或CMDB系统上面根据ip搜索,查出结果后,切换到“关联拓扑”,如下查看:
解决方法:通知NOC和机器负责人停掉突发流量
2. 交换机端口异常
现象:某交换机下面某个ip或者多个ping丢包或者业务超时
原因:交换机端口有错包
查找方法:在网管系统(或CMDB系统)查到ip后切换到“关联质量”,查看丢包率参数

解决方法:临时解决--更换交换机端口;长久解决---OS/硬件维修
3. 网卡速率降低
现象:某交换机下面某个ip 和其它任何ip通信时延变长,甚至丢包超时,流量还可能被削峰
原因:由于端口或者网线问题,网卡速率从1000M变成100M
查看方法:登录机器,执行命令ethtool eth1
异常时

正常时:

解决方法:更换网线,更换交换机端口
4. 跨城专线问题
现象:异地同步失败量明显上涨,ping有丢包
原因:专线流量不均衡;专线设备故障;专线跑满
查看方法:
使用带tos的ping,查看丢包率,超过0.3%即为异常

解决方法:使专线负载均衡;更换设备;限制异常突发流量
5. 同城专线问题
现象:大规模的IDC之间通信异常,丢包或者超时
原因:某条光纤中断,光纤有错包或者容量跑满
解决方法:流量迁移,修复错包
BTW:网络等基础架构异常或者故障大多数情况下我们是无法直接处理的,需要推动网平(直接接口人NOC)去处理,建立RTX群,把相关业务负责人,连线NOC拉到群里,以最简洁的方式描述现象和可能的问题。
分享到:
 收藏
收藏
收藏
评论排行
- ·Windows(Win7)下用Xming...(92)
- ·使用jmx client监控activemq(20)
- ·Hive查询OOM分析(14)
- ·复杂网络架构导致的诡异...(8)
- ·使用 OpenStack 实现云...(7)
- ·影响Java EE性能的十大问题(6)
- ·云计算平台管理的三大利...(6)
- ·Mysql数据库复制延时分析(5)
- ·OpenStack Nova开发与测...(4)
- ·LTPP一键安装包1.2 发布(4)
- ·Linux下系统或服务排障的...(4)
- ·PHP发布5.4.4 和 5.3.1...(4)
- ·RSYSLOG搭建集中日志管理服务(4)
- ·转换程序源码的编码格式[...(3)
- ·Linux 的木马程式 Wirenet 出现(3)
- ·Nginx 发布1.2.1稳定版...(3)
- ·zend framework文件读取漏洞分析(3)
- ·Percona Playback 0.3 development release(3)
- ·运维业务与CMDB集成关系一例(3)
- ·应该知道的Linux技巧(3)
频道总排行