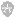使用Storm实现实时大数据分析!
2013-01-12 19:10:27 来源:互联网 评论:0 点击:
随着数据体积的越来越大,实时处理成为了许多机构需要面对的首要挑战。Shruthi Kumar和Siddharth Patankar在Dr.Dobb’s上结合了汽车超速监视,为我们演示了使用Storm进行实时大数据分析。CSDN在此编译

简单和明了,Storm让大数据分析变得轻松加愉快。
当今世界,公司的日常运营经常会生成TB级别的数据。数据来源囊括了互联网装置可以捕获的任何类型数据,网站、社交媒体、交易型商业数据以及其它商业环境中创建的数据。考虑到数据的生成量,实时处理成为了许多机构需要面对的首要挑战。我们经常用的一个非常有效的开源实时计算工具就是Storm —— Twitter开发,通常被比作“实时的Hadoop”。然而Storm远比Hadoop来的简单,因为用它处理大数据不会带来新老技术的交替。
Shruthi Kumar、Siddharth Patankar共同效力于Infosys,分别从事技术分析和研发工作。本文详述了Storm的使用方法,例子中的项目名称为“超速报警系统(Speeding Alert System)”。我们想实现的功能是:实时分析过往车辆的数据,一旦车辆数据超过预设的临界值 —— 便触发一个trigger并把相关的数据存入数据库。
Storm
对比Hadoop的批处理,Storm是个实时的、分布式以及具备高容错的计算系统。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时;也就是说,所有的信息都会被处理。Storm同样还具备容错和分布计算这些特性,这就让Storm可以扩展到不同的机器上进行大批量的数据处理。他同样还有以下的这些特性:
- 易于扩展。对于扩展,你只需要添加机器和改变对应的topology(拓扑)设置。Storm使用Hadoop Zookeeper进行集群协调,这样可以充分的保证大型集群的良好运行。
- 每条信息的处理都可以得到保证。
- Storm集群管理简易。
- Storm的容错机能:一旦topology递交,Storm会一直运行它直到topology被废除或者被关闭。而在执行中出现错误时,也会由Storm重新分配任务。
- 尽管通常使用Java,Storm中的topology可以用任何语言设计。
当然为了更好的理解文章,你首先需要安装和设置Storm。需要通过以下几个简单的步骤:
- 从Storm官方下载Storm安装文件
- 将bin/directory解压到你的PATH上,并保证bin/storm脚本是可执行的。
Storm组件
Storm集群主要由一个主节点和一群工作节点(worker node)组成,通过 Zookeeper进行协调。
主节点:
主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这个很类似于Hadoop中的Job Tracker。
工作节点:
工作节点同样会运行一个后台程序 —— Supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或者集群。
Zookeeper
Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm中的“topology”。topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream Groupings进行连接的图。下面对出现的术语进行更深刻的解析。
Spout:
简而言之,Spout从来源处读取数据并放入topology。Spout分成可靠和不可靠两种;当Storm接收失败时,可靠的Spout会对tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成功与否只发射一次。而Spout中最主要的方法就是nextTuple(),该方法会发射一个新的tuple到topology,如果没有新tuple发射则会简单的返回。
Bolt:
Topology中所有的处理都由Bolt完成。Bolt可以完成任何事,比如:连接的过滤、聚合、访问文件/数据库、等等。Bolt从Spout中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt进行处理。而Bolt中最重要的方法是execute(),以新的tuple作为参数接收。不管是Spout还是Bolt,如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
Stream Groupings:
Stream Grouping定义了一个流在Bolt任务间该如何被切分。这里有Storm提供的6个Stream Grouping类型:
1. 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。
2. 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。
3. 全部分组(All grouping):tuple被复制到bolt的所有任务。这种类型需要谨慎使用。
4. 全局分组(Global grouping):全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task。
5. 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)。
6. 直接分组(Direct grouping):这是一个特别的分组类型。元组生产者决定tuple由哪个元组处理者任务接收。
当然还可以实现CustomStreamGroupimg接口来定制自己需要的分组。
项目实施
当下情况我们需要给Spout和Bolt设计一种能够处理大量数据(日志文件)的topology,当一个特定数据值超过预设的临界值时促发警报。使用Storm的topology,逐行读入日志文件并且监视输入数据。在Storm组件方面,Spout负责读入输入数据。它不仅从现有的文件中读入数据,同时还监视着新文件。文件一旦被修改Spout会读入新的版本并且覆盖之前的tuple(可以被Bolt读入的格式),将tuple发射给Bolt进行临界分析,这样就可以发现所有可能超临界的记录。
下一节将对用例进行详细介绍。
临界分析
这一节,将主要聚焦于临界值的两种分析类型:瞬间临界(instant thershold)和时间序列临界(time series threshold)。
- 瞬间临界值监测:一个字段的值在那个瞬间超过了预设的临界值,如果条件符合的话则触发一个trigger。举个例子当车辆超越80公里每小时,则触发trigger。
- 时间序列临界监测:字段的值在一个给定的时间段内超过了预设的临界值,如果条件符合则触发一个触发器。比如:在5分钟类,时速超过80KM两次及以上的车辆。
Listing One显示了我们将使用的一个类型日志,其中包含的车辆数据信息有:车牌号、车辆行驶的速度以及数据获取的位置。
| AB 123 | 60 | North city |
| BC 123 | 70 | South city |
| CD 234 | 40 | South city |
| DE 123 | 40 | East city |
| EF 123 | 90 | South city |
| GH 123 | 50 | West city |
这里将创建一个对应的XML文件,这将包含引入数据的模式。这个XML将用于日志文件的解析。XML的设计模式和对应的说明请见下表。
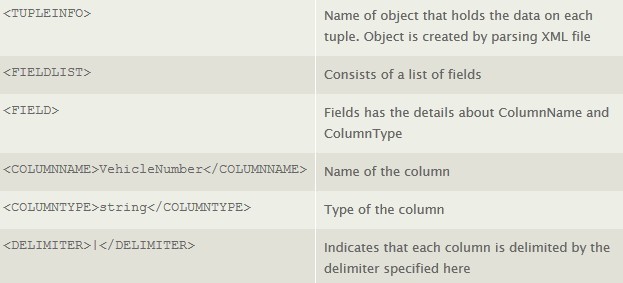
XML文件和日志文件都存放在Spout可以随时监测的目录下,用以关注文件的实时更新。而这个用例中的topology请见下图。
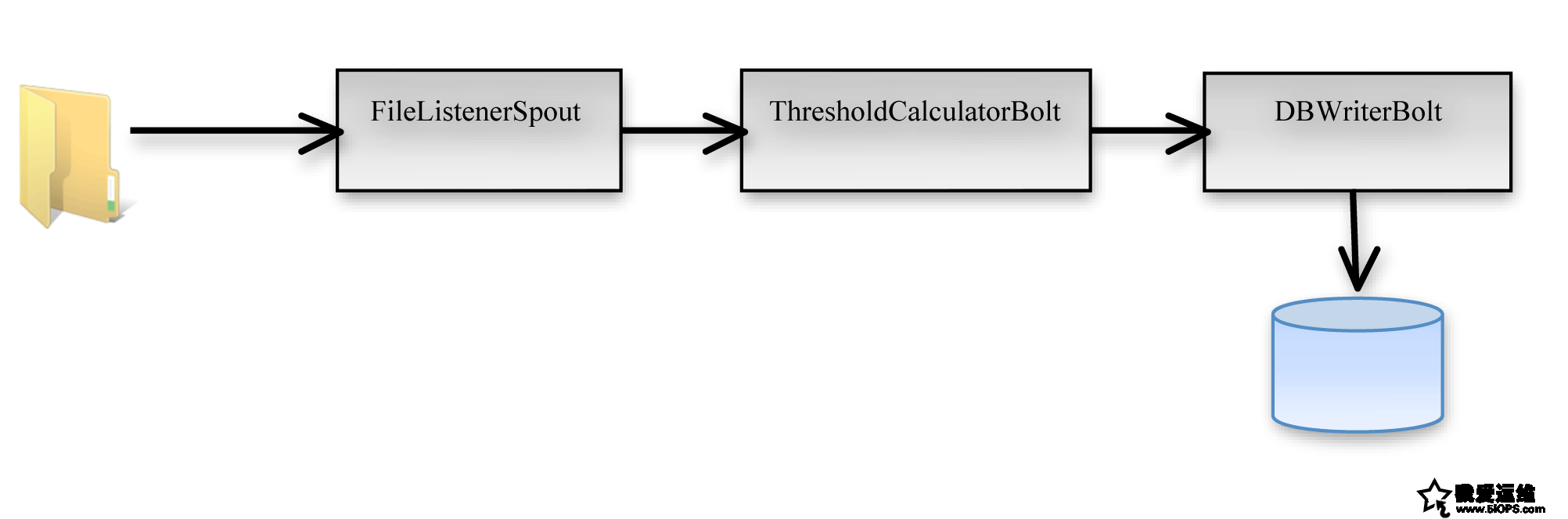
Figure 1:Storm中建立的topology,用以实现数据实时处理
如图所示:FilelistenerSpout接收输入日志并进行逐行的读入,接着将数据发射给ThresoldCalculatorBolt进行更深一步的临界值处理。一旦处理完成,被计算行的数据将发送给DBWriterBolt,然后由DBWriterBolt存入给数据库。下面将对这个过程的实现进行详细的解析。
Spout的实现
Spout以日志文件和XML描述文件作为接收对象。XML文件包含了与日志一致的设计模式。不妨设想一下一个示例日志文件,包含了车辆的车牌号、行驶速度、以及数据的捕获位置。(看下图)
Figure2:数据从日志文件到Spout的流程图
Listing Two显示了tuple对应的XML,其中指定了字段、将日志文件切割成字段的定界符以及字段的类型。XML文件以及数据都被保存到Spout指定的路径。
Listing Two:用以描述日志文件的XML文件。
-
<TUPLEINFO>
- <FIELDLIST>
- <FIELD>
- <COLUMNNAME>vehicle_number</COLUMNNAME>
- <COLUMNTYPE>string</COLUMNTYPE>
- </FIELD>
- <FIELD>
- <COLUMNNAME>speed</COLUMNNAME>
- <COLUMNTYPE>int</COLUMNTYPE>
- </FIELD>
- <FIELD>
- <COLUMNNAME>location</COLUMNNAME>
- <COLUMNTYPE>string</COLUMNTYPE>
- </FIELD>
- </FIELDLIST>
- <DELIMITER>,</DELIMITER>
- </TUPLEINFO>
通过构造函数及它的参数Directory、PathSpout和TupleInfo对象创建Spout对象。TupleInfo储存了日志文件的字段、定界符、字段的类型这些很必要的信息。这个对象通过XSTream序列化XML时建立。
Spout的实现步骤:
- 对文件的改变进行分开的监听,并监视目录下有无新日志文件添加。
- 在数据得到了字段的说明后,将其转换成tuple。
- 声明Spout和Bolt之间的分组,并决定tuple发送给Bolt的途径。
Spout的具体编码在Listing Three中显示。
Listing Three:Spout中open、nextTuple和delcareOutputFields方法的逻辑。
-
public void open( Map conf, TopologyContext context,SpoutOutputCollector collector )
- {
- _collector = collector;
- try
- {
上一篇:网站统计中的数据收集原理及实现(二)
下一篇:大数据定义和十大应用案例
分享到:
 收藏
收藏
收藏
评论排行
- ·Windows(Win7)下用Xming...(92)
- ·使用jmx client监控activemq(20)
- ·Hive查询OOM分析(14)
- ·复杂网络架构导致的诡异...(8)
- ·使用 OpenStack 实现云...(7)
- ·影响Java EE性能的十大问题(6)
- ·云计算平台管理的三大利...(6)
- ·Mysql数据库复制延时分析(5)
- ·OpenStack Nova开发与测...(4)
- ·LTPP一键安装包1.2 发布(4)
- ·Linux下系统或服务排障的...(4)
- ·PHP发布5.4.4 和 5.3.1...(4)
- ·RSYSLOG搭建集中日志管理服务(4)
- ·转换程序源码的编码格式[...(3)
- ·Linux 的木马程式 Wirenet 出现(3)
- ·Nginx 发布1.2.1稳定版...(3)
- ·zend framework文件读取漏洞分析(3)
- ·Percona Playback 0.3 development release(3)
- ·运维业务与CMDB集成关系一例(3)
- ·应该知道的Linux技巧(3)
频道总排行