轻松应对IDC机房带宽突然暴涨问题
2012-06-27 15:56:05 来源:互联网 评论:0 点击:
【提出问题】【实际案例一】凌晨3:00点某公司(网站业务)的一个IDC机房带宽流量突然从平时高峰期150M猛增至1000M,如下图:该故障的影响:...

【提出问题】
【实际案例一】
凌晨3:00点某公司(网站业务)的一个IDC机房带宽流量突然从平时高峰期
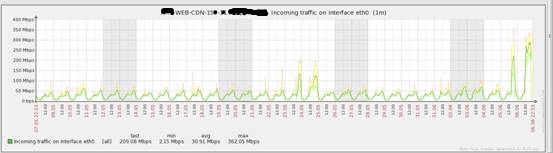
该故障的影响:直接导致数百台服务器无法连接,该机房全部业务中断。
某年某月某日夜老男孩接到学生紧急求助,公司网站(web游戏业务)平时几十M带宽,结果突然跑满100M,持续100M已经很久。事后,该学生的总结开头如下,
凌晨一点接到报警短信,网站无法访问。立马拿起笔记本上网查看,发现整个机柜的网络都无法正常访问。第一感觉是不是IDC网络出问题了,给机房打电话反馈回来的信息是机房网络正常,但是带宽流量异常(100M带宽的流量峰值已跑瞒)。
该故障的影响:直接导致数十台服务器无法连接,该机房全部业务中断,且故障持续时间长。
【实际案例三】
某月某日,接到运维的朋友紧急求助,其公司的CDN源站,源站的流量没有变动,CDN那边的流量无故超了好几个G,不知道怎么处理? 老男孩补充,曾遇到过一张图片不到一天,跑了20多T的一张流量。
该故障的影响:由于是购买的CDN,虽然流量多了几个G,但是业务未受影响,但是,这么大的异常流量,持续下去可直接导致公司无故损失数万元。解决这个问题体现运维的价值。
事不过三,暂时先举3个例子吧。这三个案例都是运维工作中实际遇到的故障,事发突然且需要紧急处理。在实际论坛或群里看到朋友反馈的此类问题,也多达数次,其中差不多各种鸟都有,老鸟、中鸟,小鸟。
大部分朋友解决起来,脑袋里没思路(反射弧直接定位DDOS),解决起来耗时长,造成的了业务长时间中断。老鸟解决起来也是按部就班,首先会反射为DDOS问题,结果解决时间加长了,如果能提前做好预案,恢复速度可能就会好很多,下面老男孩就来谈下个人的一些看法。
2 【分析问题】
1)IDC带宽被占满的原因很多,常见的有:
a.真实遭受DDOS攻击(遇到过几次,造成影响的不多见,其中还有黑客勒索的案例)。
b.内部服务器中毒,大量外发流量(这个问题老男孩接警5次以上)
c.网站元素(如图片)被盗连,在门户页面被推广导致大量流量产生(接警3次以上)
d.合作公司来抓数据,如:对合作单位提供了API数据接口(有合作的公司的朋友了解这个)
e.购买了CDN业务,CDN猛抓源站(这个次数也不少)。
f.其他原因还有一些,不普遍就不提了。
2)CDN带宽异常,源站没异常。
这类问题基本都是缓存在CDN的数据被频繁访问引起的。解决方法见结尾案例。
3) CDN带宽异常,源站也异常。
可能原因如公司做推广,大量数据访问,热点数据cache里不全。或CDN问题导致数据回源(有关CDN回源率问题及提升回源率经验,以后再和大家分享)。影响就是带宽高,后端静态服务器及图片及存储压力大(解决办法参考7层门户网站架构案例文章http://www.5iops.com/html/2012/cdn_0627/134.html)
3 【解决问题】
分析了问题的可能原因,就好比较排查了。
a.真实遭受DDOS攻击
DDOS问题的解决可参考《网站DDOS攻击防护实战经验集》(http://www.5iops.com/html/2012/security_0627/135.html),提供了17条解决经验思路,供大家参考,这里就不提了,那么实际上
遭受真实DDOS攻击并产生影响的并不是最常见的。
b.内部服务器中毒,大量外发流量。
这个问题的解决比较简单,可能有的朋友说,看看服务器流量,哪个机器带宽高处理下就好了。其实不然,实际解决比这复杂得多,带宽打满,所有监控都是看不到的。
比较好的思路,是联系机房确定机房自身无问题后(机房一般没法帮我们的),请机房断开连接外部IP服务器的网线,如负载均衡器,仅保留VPN SERVER,然后断掉内部服务器出网光关的线路,切断外发流量源头。
接下来查看监控流量服务,判断外发流量的服务器,然后进行处理。
其实,这个问题的发生及快速定位和很多公司的运维规范、制度关系很大,老男孩在给一些公司做运维培训分享时发现这个问题很严重(表象很好,内部运维规范、制度欠缺很多),大家都讨论的很深入,实际用的还是和聊的有差距。。
比如有的公司开发直接FTP连接随时发布代码,或者由开发人员负责定时多次上线。而运维人员又不知晓,结果导致问题发生定位时间长,这点建议各公司的老大多思考下。
老男孩的运维思路是,如果把网站机房比喻为一座房子,那首先要堵住后门(内部),其次是监控好前门(做好安全,留个小窗户给外面人看,即80端口服务,同时安排站岗值班的)。
网站的无休止的随时随意发布代码,对网站的稳定影响是至关重要的。对运维人员对故障的定位快慢也很关键。根据老男孩不完全调查,约50%以上的重要运维故障都是程序代码导致的,这也是老男孩给企业做培训分享时,灌输建议CTO的,多把网站稳定的责任分给开发,而不是运维。如果这个思想不扭转,网站不稳定状况就难以改变。
c.网站元素(如图片)被盗连
这个属于网站的基本优化了,apache,lighttpd,nginx都有防盗链的方案,必须要搞。说到这也提个案例,老男孩的一个学生,到了企业工作,发现人家网站没有防盗链,结果上来没有周知老大,直接做防盗链了,然后美滋滋的当时还给我留言,说给公司搞防盗链了,很有成就,结果导致公司对外合作的业务,都是小叉子了,幸亏发现的及时没出大问题。
d-e.合作公司来抓数据,如:对合作单位提供了API数据接口或购买了CDN业务。
最常见的就是购买CDN服务,如:CDN新建一个节点(可能数十机器),直接来我们IDC原战来抓数据(有的做好点的夜里来抓)。把原站抓的流量暴涨,严重的导致服务宕机。几家CDN公司,都有过这样的问题。这点希望CDN公司看到了,能改善,毕竟用户上帝嘛。
当然和电信,联通,GOOGLE,BAIDU,词霸等公司的合作,也会有流量暴高的情况,这里面包括了为合作的站搜索引擎爬虫爬数据的问题。有时虽然带宽流量不高,但是服务器或数据库撑不住了,搜索引擎专门喜欢爬我们的站内搜索,DISCUZ,CMS等早期的开源程序的搜索都是全站like %%方式去数据库搜索的,几个爬虫过来,直接就挂掉了,当然这不是本文要讨论的,解决方案以后再聊。
f.其他原因还有一些,不普遍就不提了。
上面的几点比较常见,其他原因就不多见了,因此,作罢,打这么多字真不轻松啊。
4 【苦练内功】
首先,老男孩强调下,大家要经常培养下自己的心里素质,遇到问题不能发慌。遇到不少朋友,处理紧急故障时,大脑都空白缺血了,手抖的无法敲击键盘了,这样的状态如何解决故障呢?如果老大在后面看着就更是雪上加霜了,甚至有个别学生直接跟老男孩哭鼻子了,宕机几分钟损失上万,负不起责任。
其实上面的大家的表现都是正常的,没什么不对的,曾经老男孩也是这样过来的,也是不断的挑战自己才练出来的。
希望朋友们能多提前做功课,不要问题来了在思考解决办法,临时的应对一定会是手忙脚乱的,即使是老鸟。如果提前有预案和防范演练,问题发生后就坦然得多,这可以扩展到运维的方方面面,DB,WEB,备份,恢复,流量等。
5 【亡羊补牢】
发生问题后,要充分总结,争取下次发生了,能提升速度,当然最好不发生。其实,运维人员挺悲催的,开发的下班就没事了,我们还得7*24开手机,来个短信提心吊胆的,甚至看到有个门户DBA发微薄,说making love时都可能被报警短信打断。1、提前优化运维制度、规范。2、提前优化网站结构、单点故障。3、留足备用带宽及服务器资源,把控好风险。4、完善的监控策略及响应机制等。
尽量不打无准备之战。兵法云,知己知彼,百战不殆。运维又何尝不是这个理?
6 【实战解决案例】
说了这么多了,都是理论,再给个案例吧【摘自老男孩Linux培训-shell培训教案中的例子】,这里要特别感谢白开水兄弟给予的支持。
下面的例子适合于网站流量很高,但是,还没达到全网瘫痪的严重地步时的解决方案,适合我们自己的IDC机房及CDN业务(如果是CDN,那么,分析处理可以交给CDN,自己下载CDN日志分析也可)。
范例7:分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小
说明:范例7的生产环境应用:这个功能可以用于IDC及CDN网站流量带宽很高,然后通过分析服务器日志哪些元素占用流量过大,进而进行优化裁剪该图片(见老男孩发布的《淘宝的双十一超大流量应对文章点评》),压缩js等措施。
本题需要输出三个指标: 【访问次数】 【访问次数*单个文件大小】 【文件名(可以带URL)】
解答:
测试数据
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299"http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299"http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:44:02 +0800] "GET /static/flex/vedioLoading.swf HTTP/1.1" 200 3583"http://oldboy.blog.51cto.com/static/flex/AdobeVideoPlayer.swf?width=590&height=328&url=/[[DYNAMIC]]/2" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
124.115.4.18 - - [08/Dec/2010:15:44:15 +0800] "GET /?= HTTP/1.1" 200 46232 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/web_js.js HTTP/1.1" 200 4460 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/jquery.lazyload.js HTTP/1.1" 200 1627 "-" "-"
法一:通过两个数组来计算
因为我们要的最终结果是某个文件的访问次数和消耗的流量,所以考虑建立以文件名为索引的两个数组,一个存储访问次数,一个保存消耗的流量,这样当使用awk按行遍历文件时,对次数数组+1,同时对流量数组进行文件大小的累加,等文件扫描完成,再遍历输出两个数组既可以得到该文件的反问次数和总的流量消耗。
[root@locatest scripts]# awk '{array_num[$7]++;array_size[$7]+=$10}END{for(x in array_num){print array_size[x],array_num[x],x}}' access_2010-12-8.log |sort -rn -k1|head -10 >1.log
法二:
[root@locatest scripts]# awk '{print $7"\t" $10}' access_2010-12-8.log|awk '{S[$1]+=$2;S1[$1]+=1}END{for(i in S) print S[i],S1[i],i}'|sort -rn|head -10 >2.log
[root@locatest scripts]# diff 1.log 2.log
[root@locatest scripts]# cat 1.log
57254 1 /static/js/jquery-jquery-1.3.2.min.js
46232 1 /?=
44286 1 //back/upload/course/2010-10-25-23-48-59-048-18.jpg
33897 3 /static/images/photos/2.jpg
11809 1 /back/upload/teacher/2010-08-30-13-57-43-06210.jpg
10850 1 /back/upload/teacher/2010-08-06-11-39-59-0469.jpg
6417 1 /static/js/addToCart.js
4460 1 /static/js/web_js.js
3583 2 /static/flex/vedioLoading.swf
2686 1 /static/js/default.js
分享到:
 收藏
收藏
收藏
评论排行
- ·Windows(Win7)下用Xming...(92)
- ·使用jmx client监控activemq(20)
- ·Hive查询OOM分析(14)
- ·复杂网络架构导致的诡异...(8)
- ·使用 OpenStack 实现云...(7)
- ·影响Java EE性能的十大问题(6)
- ·云计算平台管理的三大利...(6)
- ·Mysql数据库复制延时分析(5)
- ·OpenStack Nova开发与测...(4)
- ·LTPP一键安装包1.2 发布(4)
- ·Linux下系统或服务排障的...(4)
- ·PHP发布5.4.4 和 5.3.1...(4)
- ·RSYSLOG搭建集中日志管理服务(4)
- ·转换程序源码的编码格式[...(3)
- ·Linux 的木马程式 Wirenet 出现(3)
- ·Nginx 发布1.2.1稳定版...(3)
- ·zend framework文件读取漏洞分析(3)
- ·Percona Playback 0.3 development release(3)
- ·运维业务与CMDB集成关系一例(3)
- ·应该知道的Linux技巧(3)
频道总排行